Dokumentextraktion¶
Die Read-File-Komponente kann die Dateiverarbeitung an den KARLI-Dokumentextraktions-Dienst delegieren und so strukturierte Extraktion aus Dokumenten und Audio mittels spezialisierter Modelle ermöglichen.
Extraktions-Backend¶
Das Dropdown Extraction Backend der Komponente legt fest, wie Dateien verarbeitet werden:
| Backend | Verhalten |
|---|---|
docling (Standard) |
Dateien werden lokal über die Upstream-Langflow-/Docling-Pipeline verarbeitet. |
karli |
Dateien werden an den KARLI-Extraktionsdienst gesendet, der strukturierte Inhalte zurückgibt. |
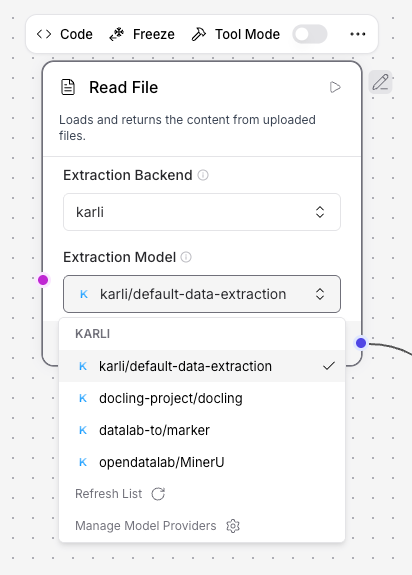
Modellauswahl¶
Steht Extraction Backend auf karli, erscheint zusätzlich das Feld Model. Das Dropdown wird dynamisch vom KARLI-Provider befüllt — KARLI ist derzeit der einzige Anbieter von Datenextraktions-Modellen.
Unter Modelle → Datenextraktion findet sich die vollständige Modellliste samt akzeptierter Dateitypen. Die Komponente prüft die hochgeladene Datei vor dem Upload gegen den akzeptierten Typ des gewählten Modells (ein PDF an das Whisper-Modell zu schicken, liefert z. B. einen Fehler statt eines Uploads).
Authentifizierung¶
Ist das karli-Backend gewählt, authentifizieren sich Extraktions-Requests mit folgender Priorität:
- JWT (bei aktiver Karli-Studio-Session) — gesendet als
Authorization: Bearer <token>. KARLI_API_KEY(aus Komponentenattribut, Provider-Variablen oder der UmgebungsvariableKARLI_API_KEY) — gesendet alsX-API-Key: <key>.- Fehler — sind weder JWT noch Key verfügbar, wird ein
ValueErrorausgelöst mit dem Hinweis,KARLI_API_KEYzu konfigurieren oder über Karli Studio zuzugreifen.
Info
KARLI_API_KEY ist nur relevant beim direkten Zugriff auf die Agentlab-API ohne Karli-Studio-Session. Studio-Nutzer müssen dieses Feld nicht konfigurieren. Siehe die Model-Provider-Übersicht für Details zu den Zugangsdaten.
Ablauf¶
Ist die Extraktion aktiviert, sendet die Komponente einen Multipart-POST an {KARLI_BASE_URL}/data-extraction/extract. Das Formularfeld extractorModel trägt das gewählte Modell (gemappt auf seinen KARLI-Identifier), der File-Part enthält das Dokument. Der Dienst liefert eine JSON-Antwort, deren segments zu einem Text zusammengefügt werden — Segmente mit title erscheinen als ## <title>-Markdown-Überschriften.
flowchart LR
Upload["Datei-Upload"] --> RF["Read File"]
RF --> KES["KARLI-Extraktionsdienst"]
KES --> Out["Strukturierte Ausgabe"]
Der Output nach unten ist ein Data mit:
| Feld | Beschreibung |
|---|---|
file_path |
Ursprünglicher lokaler Pfad der hochgeladenen Datei. |
exported_content |
Der zusammengesetzte Text (mit ## <title>-Überschriften pro Segment). |
export_format |
Für dieses Backend stets KARLI. |
task_id |
Die Task-ID des KARLI-Extraktionsauftrags — nützlich für Tracing. |
model |
Der Identifier des verwendeten Modells. |
Zusammenfassung der Einstellungen¶
| Einstellung | Beschreibung |
|---|---|
| Extraction Backend | docling (lokal) oder karli (KARLI-Dienst). |
| Model | Nur sichtbar, wenn das karli-Backend aktiv ist. |